Reducing latency in AI Speech Synthesis
Reducing latency in AI Speech Synthesis
By Dave Bitter
4 min read
AI-powered speech synthesis is getting incredibly realistic. This opens up many possibilities to generate realistic audio based on the text you provide. Whilst relatively fast, the latency still isn’t low enough for “real-time synthesis”. Let’s optimise that!

- Authors

- Name
- Dave Bitter
In my previous article, I showed how you can interact with ChatGPT through Voice UI on the web. If you haven’t already, read that article first to know what I built. What sells the illusion of having a real-time conversation with the AI is the low latency. Because the response is so quick, it doesn’t feel like the AI needs to process your information and create an audio file to playback to you. Even though this part feels realistic, the robotic voice for the speech synthesis doesn’t. My colleague Christofer Falkman pointed me to a way I could make Aiva, the ChatGPT-powered assistant, even more realistic. Using ElevenLabs’s AI-powered speech synthesis I can replace this robotic voice with an incredibly realistic voice. Time to upgrade Aiva!
Let’s implement it
As you might remember from the previous article, Aiva works like this:
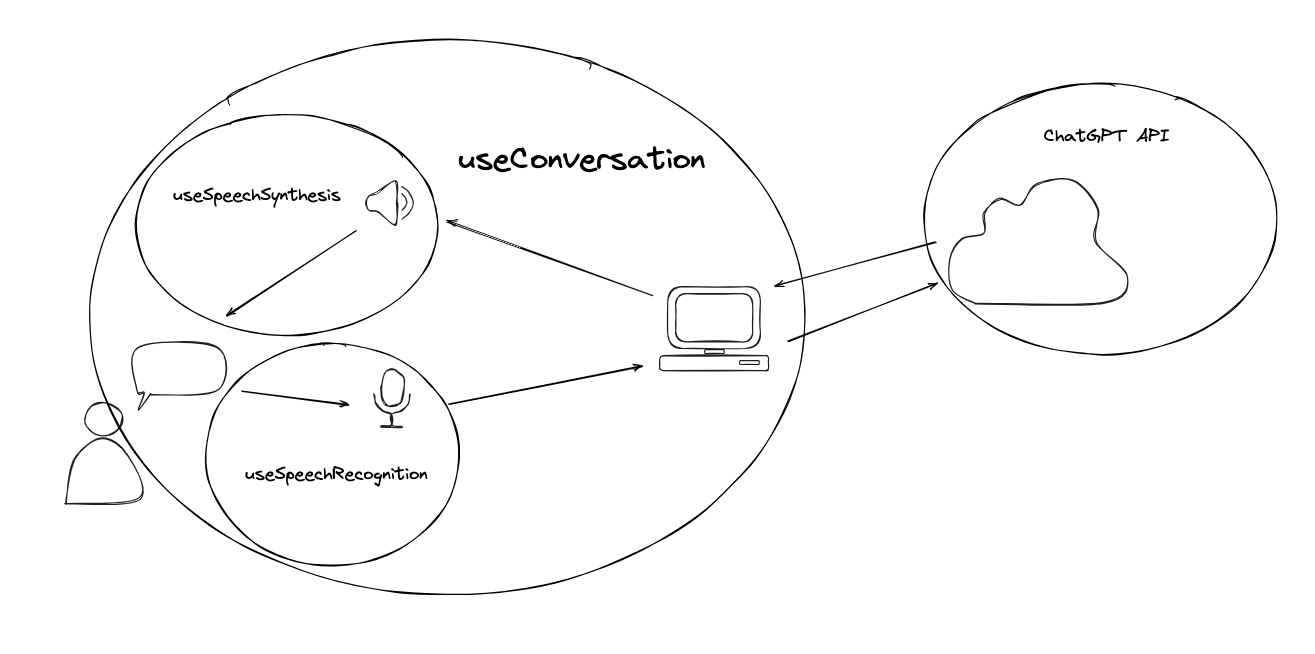
Instead of using the native SpeechSynthesis Web API, we now replace it with a call to the ElevenLabs API where we get returned binary data in the form of a buffer. Or, simplified, we get a bit of data we can play as audio. As soon as the entire piece of text is sent to that API, returned to the application, and played as audio, the user gets to talk again. This yields a pretty cool result with an incredibly realistic voice:
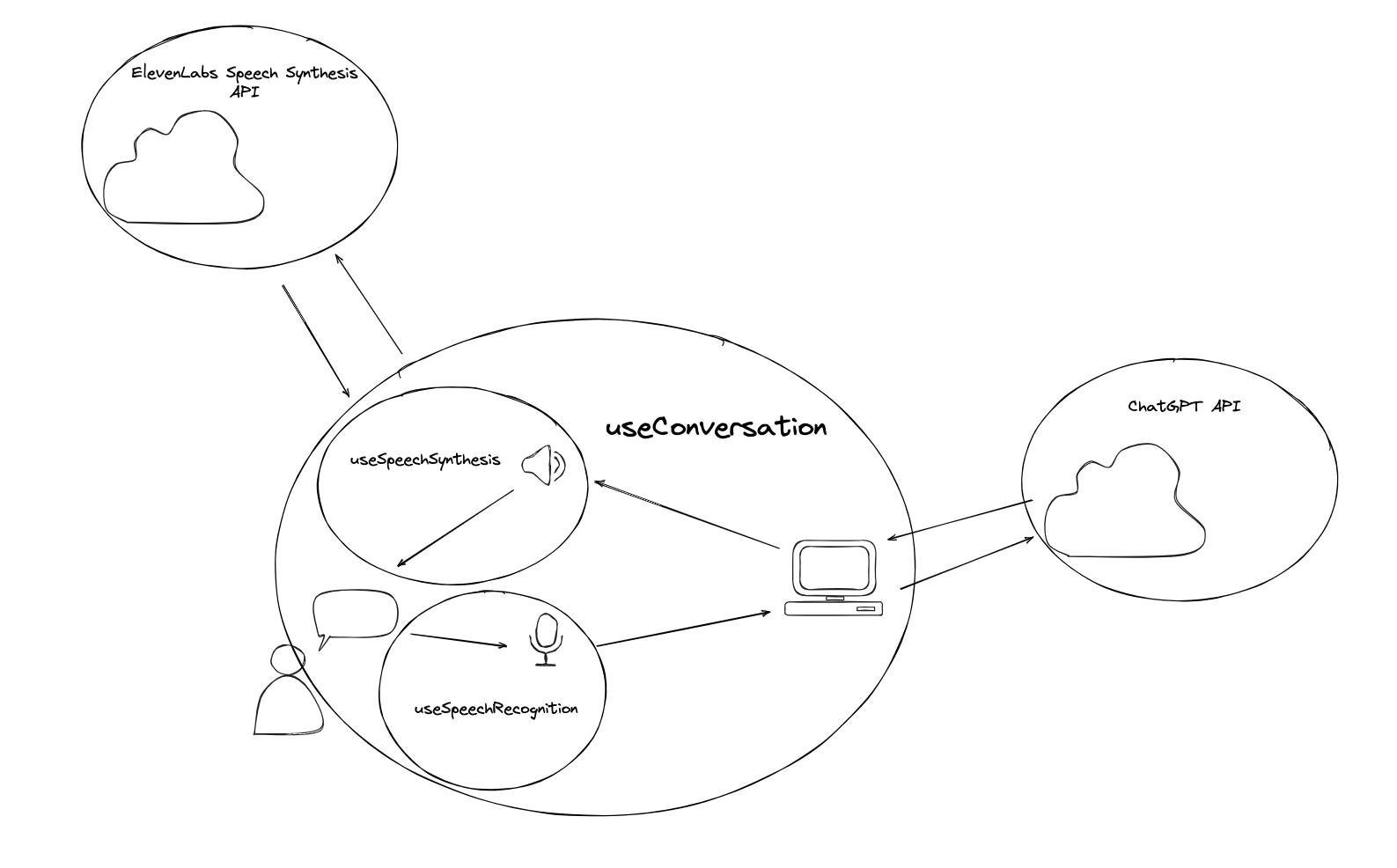
It’s slow!
You might notice that the AI-powered speech synthesis is quite a bit slower. The latency increases with the length of the text. It first needs to turn all of the text into audio before it can play the first sentence. The longer the text, the slower the response. This is breaking the user experience of having a natural conversation.
Low latency over realistic voice
In my opinion, having a low-latency robotic voice in a real-time conversation is a better user experience. It doesn’t take you out of the conversation as much. So what now? Don’t use the AI version? Of course not, let’s fix this!
Time to take some well-known approaches
First, I looked into whether the audio could be streamed from the API. Unfortunately, I couldn’t find this option and didn’t want to limit my choice of which AI-power speech synthesis products I could use. Then, I thought about how, as a developer, I would normally handle large slow requests. Imagine you are making a dashboard with 10.000 rows of data. You could opt for pagination where you click a button to go to the next page of results. Chunking the data in pages of rows works great. Taking this into a conversation, we could chunk the text into sentences and play the audio for each sentence. Whilst this is the approach I took, this posed a new problem. Let’s imagine I retrieve audio for a sentence of the text, play the audio, and then do this over and over again for the entire piece of text. This means that the latency is pretty much just split up, but still present:
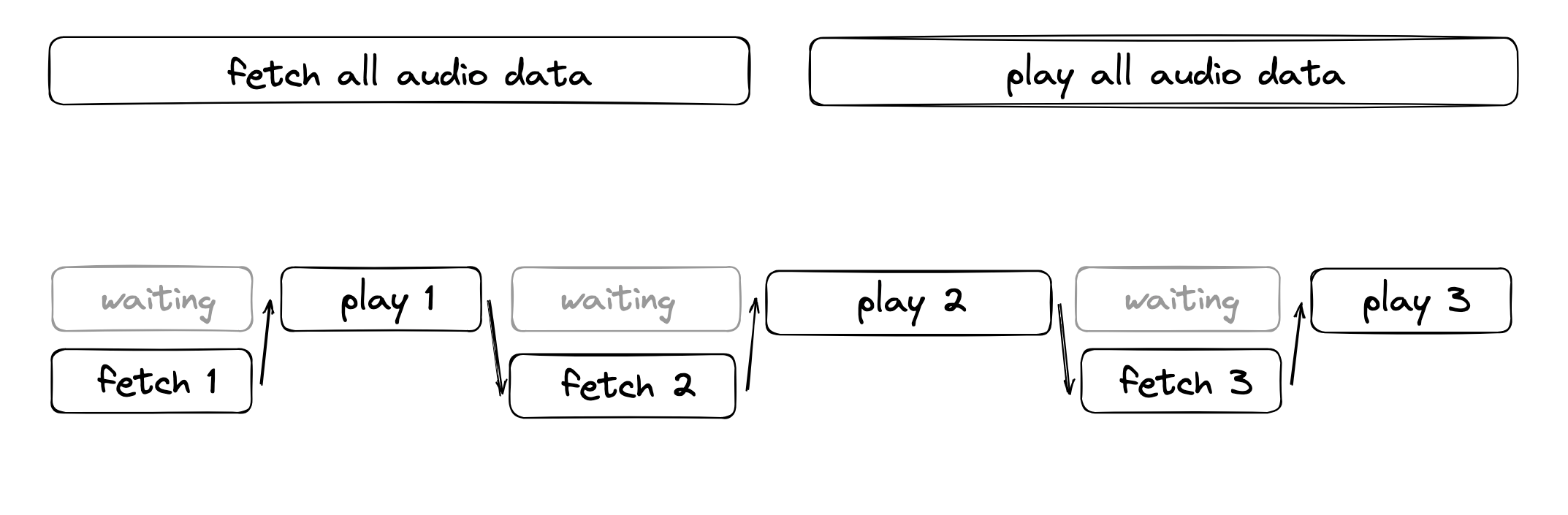
As you can see, there is quite a bit of time while the audio is playing which I could utilize to retrieve the audio data for the next sentence. This is pretty similar to how humans talk. You think of what to say and while you are talking you’re already thinking of the next sentence. This results in a fluent flow where there is always audio playing:

The end result
That did the trick! The latency is now low enough to not intrude on the natural flow of the conversation: