An Introduction to RAG
An Introduction to RAG
By Wouter Heldens
4 min read
Fed up with AI that makes up facts and can't keep up with your latest data? That's where RAG (Retrieval-Augmented Generation) comes in – the clever technique that's changing how we build AI applications that actually work.
- Authors

- Name
- Wouter Heldens
Why RAG Matters
Retrieval Augmented Generation (RAG) is an innovative approach that enhances AI capabilities by seamlessly integrating language models with external information retrieval systems. This powerful combination allows AI to access and utilize up-to-date data from a wide range of sources when generating responses. By doing so, RAG significantly improves the accuracy and relevance of AI-generated content, effectively overcoming the inherent limitations of traditional language models that rely solely on pre-trained knowledge.
How does it work
Under the hood, RAG typically uses vector databases to store embeddings and connects them to language models that generate the final responses. The key principle to remember is that:
It's all about giving AI access to the right information at the right time.
The Magic Happens in Two Steps:
The Retrieval Part Your documents are split into chunks and converted into embeddings (also known as "semantic vectors"). When a question comes in, RAG finds the most relevant pieces from your documentation.
The "most relevant pieces" are chunks of text from your documentation that are semantically closest to the user's query. These pieces contain information that is most likely to be useful in answering the question or addressing the user's needs.
The Generation Part The AI model receives both the question and these relevant document pieces. It can then generate answers using current, accurate information instead of relying solely on its training data.
Vector Database
A working RAG (Retrieval-Augmented Generation) system requires a vector database containing retrievable data. Vector databases efficiently store and query high-dimensional vector representations of data, such as the semantic meanings of text or images.
In RAG applications, these databases enable fast nearest-neighbor searches based on semantic similarity, which is crucial for retrieving relevant context when generating responses.
Similarity Comparisons Based on Vectors
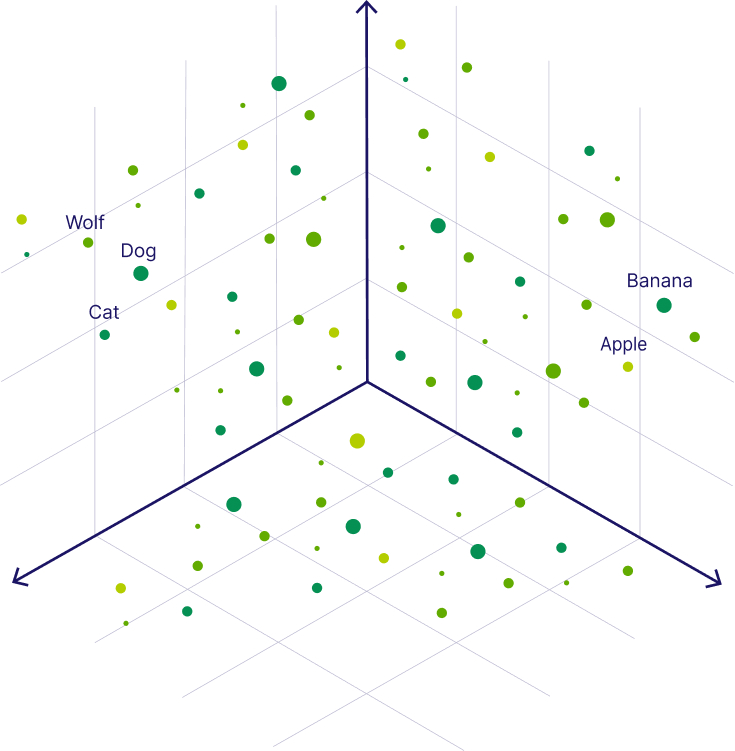
For this example, we'll use ChromaDB, an open-source vector database optimized for AI applications. It offers efficient similarity search and seamless integration with machine learning models, making it ideal for semantic search and recommendation systems.
Let's create a ChromaDB instance and populate it with data to demonstrate a RAG architecture:
Create a vectors database with some data
import chromadb
from langchain.text_splitter import RecursiveCharacterTextSplitter
# Set up ChromaDB
chroma_client = chromadb.PersistentClient(path="./chroma_db")
collection = chroma_client.get_or_create_collection(name="your_collection_name")
# Our story (This is just an example; you can get data from different sources,
# such as a PDF about the story of the three little pigs)
story = """Once upon a time, three little pigs left their mother and their home to seek their own fortunes and build their own houses.
The three little pigs gathered materials for their houses.
The first little pig chose to build his house from straw, the second little pig chose to build his house from sticks, and the third little pig chose to build his house from bricks."""
# Split the text into chunks of 100 characters with an overlap of 20
# The overlap is necessary so the LLM can keep the context and prevent information loss
text_splitter = RecursiveCharacterTextSplitter(chunk_size=100, chunk_overlap=20)
chunks = text_splitter.split_text(story)
# Add chunks to the collection
for i, chunk in enumerate(chunks):
# Get a numerical vector representation of the chunk by an embedding model.
# Next in this article you can read more about the embedding model
chunk_embedding = get_openai_embedding(chunk.page_content)
collection.add(
documents=[chunk_embedding],
metadatas=[{"source": "Three Little Pigs story"}],
ids=[f"chunk_{i}"]
)
RAG Architecture
Now that we have a vector database with some data, let's create a RAG system to ask how the third little pig built his house.
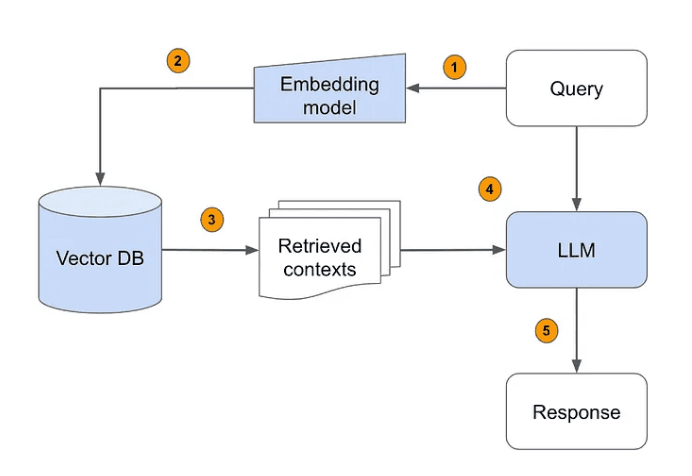
1. Query Input
The process begins with a user query, which is the initial input to the system. This query is typically a question or a request for information that the user wants the AI to address:
question = 'How did the third little pig build his house?'
2. Embedding Model
The question is passed through an embedding model, which transforms the text into a numerical vector representation. This process is crucial for enabling efficient similarity comparisons between the question and the stored knowledge.
There are several options for embedding models: OpenAI's text-embeddings-3 accessible through their API, Claude's embedding models via the Anthropic API embedding models via the Anthropic API, or open-source models from HuggingFace . Each option offers different advantages in terms of quality, cost, and ease of use.
In this example, we use the OpenAI embedding model:
# Create embedding function
def get_openai_embedding(question):
response = openai.embeddings.create(
model="text-embedding-ada-002",
input=question
)
return response.data[0].embedding
# Use the embedding function with our question
question_embedding = get_openai_embedding(question)
3. Vector Database Search (Context Retrieval)
Once we have the question embedding, we can search the vector database to retrieve relevant chunks of data based on their similarity to the question embedding:
results = collection.query(
query_embeddings=[question_embedding],
n_results=5,
where=where_filter
)
4. Language Model Processing
Now that we have both the question embedding and relevant chunks from our vector database, we can combine them in a prompt and ask OpenAI for the answer to our question. We want to know how the third pig built his house.
Besides the question, we also need a system prompt. This system prompt instructs the LLM how to handle the data and how it should behave.
When using RAG, it's better for the LLM to state that it couldn't find an answer based on the provided data rather than generate a random response. We can also specify the desired response format. In this case, we want a well-structured JSON that includes information about the answer's confidence level:
def ask_question_prompt(
documents: str,
metadata: Optional[List[Dict]] = None,
) -> str:
system_prompt = f"""
Role: Advanced Document-Based Information Retrieval Specialist
Core Principles:
1. Provide precise, document-sourced answers.
2. NEVER use external or prior knowledge.
3. Maintain transparency about information sources and limitations.
4. Ensure clear, structured, and valid JSON responses.
Response Structure Guidelines:
{{
"answer": "Comprehensive response directly from source documents.",
"answer_confidence": "high|medium|low",
"direct_quotes": [{{"quote": "Direct quote", "page_index": <index>, "source": <source>}}],
}}
If NO relevant information is found:
{{
"answer": "No relevant information in provided documents.",
"answer_confidence": "low"
}}
Detailed Response Requirements:
- Provide a comprehensive answer.
- List all relevant source documents.
Confidence Level Guidelines:
- high: Multiple direct quotes, clear context.
- medium: Some supporting evidence, partial context.
- low: Minimal or tangential information.
Additional Guidelines:
- Escape special characters.
- Maintain a professional, objective tone.
🔍 CONTEXT:
Documents: {documents}
Metadata: {metadata}
"""
return system_prompt
# Use the function to create a system prompt for the LLM
system_prompt = ask_question_prompt(results['documents'], results['metadatas'][0])
Now that we have both the system prompt and question prompt, we can create a function that asks the LLM to provide an answer:
def ask_openai_chat_model(question, system_prompt):
response = openai.chat.completions.create(
model="gpt-3.5-turbo", # You can replace this with any other model
messages=[
{"role": "system", "content": system_prompt}, # System message to set the behavior
{"role": "user", "content": question} # The user's question as the prompt
]
)
# Get the assistant's reply from the response
return response.choices[0].message.content
Using Our RAG Backend
With our RAG backend ready in Python, we can create a frontend application to utilize it. For example, we can build an interface to upload PDFs and ask questions about their content. Using this system, we can finally confirm how the third little pig built his house: with bricks.
Watch the RAG in action here: