What is WebLLM
What is WebLLM
By Jafar Rezaei
4 min read
WebLLM runs in browser to allow Models to be more accessible inside the browser and fully client side! With the evaluation of AI technologies, it is expected that WebLLM will be an important part of future applications.
- Authors

- Name
- Jafar Rezaei
WebLLM: Running LLMs in the Browser
Large Language Models (LLMs) changed the play for natural language processing (NLP) as they help implement chatbots, code generations, etc easier. As we move forward the models are getting smaller and faster and this opens a lot of opportunities. Traditionally, LLMs had to be served from powerful cloud-based GPUs and powerful servers, but recent progress made it much easier to be even possible to run in a local client-side browser. In this article, we will cover how WebLLM can help this process of serving a model fully on the client side.
What is WebLLM?
WebLLM is an approach implemented by MLC-AI team that allows LLMs to run fully locally within a browser using WebAssembly (WASM), WebGPU, and other modern web technologies. When WebLLM is used, it first downloads the chosen model and stores it locally in the CacheStorage. From that moment on, it can be used fully offline. While it might be a bit extra work to download and run a model locally, with the growth of internet speed and device capabilities, this might be a good idea in the near future.
How WebLLM Works
The technology behind WebLLM allows it to work fully in the browser without any server-side infrastructure. but how does it work?
- Use of WebAssembly (WASM) and WebGPU: It Converts the model computations into a specific format, is efficient for WebAssembly modules, and uses WebGPU for acceleration to run the model.
- Running on the Client Side: Unlike traditional cloud-based LLMs, WebLLM works fully locally and in the browser, so it does not send data to remote servers and ensures privacy and security.
- Optimized model Size: WebLLM Uses a quantized and optimized version of models so it can be faster and more efficient in a browser environment.
Cloud vs. In-Browser LLMs
Comparing Native LLM embedding vs web-based LLM embedding might be a good way to understand the differences between the two. Of course it might not be ideal for all projects, but running LLMs in the browser is a great advantage for most projects.
| Feature | LLM served from Cloud | WebLLM (In-Browser) |
|---|---|---|
| Offline Support | Limited (requires internet) | Can run offline once loaded |
| Performance | Faster (dedicated hardware) | Slower (limited by browser capabilities) |
| Privacy | Limited due to send/receive data to server | Fully private (runs locally) |
| Installation | Requires specific servers (GPUs, Memory) | Open the website and download the model |
| Portability | Limited to specific OS/hardware | Cross-platform (any modern browser) |
| Latency | Lower latency (powerful hardware) | Higher latency (browser execution overhead) |
Keep in mind that using WebLLM will require the model to be downloaded and stored locally on the client. So it is important to consider the size of the model and the amount of data that needs to be downloaded.
How Can I Implement It in My Website?
WebLLM has npm package(@mlc-ai/web-llm) to work with it, and it can be installed easily as an npm package:
npm i @mlc-ai/web-llm
Then import the module in your code and use it. It can also be dynamically imported:
const webllm = await import ("https://esm.run/@mlc-ai/web-llm");
Create MLCEngine
Most operations in WebLLM are done through MLCEngine. here is a sample code snippet
Create your LLM engine
import * as webllm from "@mlc-ai/web-llm";
const selectedModel = "Llama-3.1-8B-q4f32_1-MLC";
const engine: webllm.MLCEngineInterface = await webllm.CreateMLCEngine(
selectedModel,
{
initProgressCallback: (initProgress) => {
console.log(initProgress);
},
logLevel: "INFO",
},
);
As soon as you have the engine loaded, and ready to use, you can start calling the APIs. Note that the engine creation is asynchronous, so you need to wait until it finishes loading the model before you can use it.
const messages = [
{ role: "system", content: "You are a helpful AI assistant." },
{ role: "user", content: "Hello!" },
]
const reply = await engine.chat.completions.create({
messages,
});
console.log(reply.choices[0].message);
console.log(reply.usage);
It also supports streaming, and it can be done easily by passing stream: true property to the create method.
const chunks = await engine.chat.completions.create({
messages,
temperature: 1,
stream: true, // <-- Enable streaming
stream_options: { include_usage: true },
});
let reply = "";
for await (const chunk of chunks) {
reply += chunk.choices[0]?.delta.content || "";
console.log(reply);
if (chunk.usage) {
console.log(chunk.usage); // only last chunk has usage
}
}
Since these operations are running on the same thread of the browser, it can be a bit tricky to run them in the applications, and it can harm the performance of the application. So instead of using it directly, it is recommended to use it in a separate thread(Worker).
In browser environment, we have Web Workers, and Service Workers. Fortunately, WebLLM provides a wrapper for these APIs, so you can use it in the same way as the native API.
import * as webllm from "@mlc-ai/web-llm";
const engine = new webllm.ServiceWorkerMLCEngine();
await engine.reload("Llama-3-8B-Instruct-q4f16_1-MLC");
async function main() {
const stream = await engine.chat.completions.create({
messages: [{ role: "user", content: "Hello!" }],
stream: true,
});
for await (const chunk of stream) {
updateUI(chunk.choices[0]?.delta?.content || ""); // TO UPDATE UI
}
}
If you have worked with the OpenAI library previously, the code structure might look similar to you, the reason is that they tried to keep it similar in a way that it feels like interacting with a server via sending and receiving JSON.
It also supports media formats like image URLs. Also, there are some examples of how to use WebLLM in different projects/frameworks on mlc-ai team repository for web-llm: examples folder.
Try it out
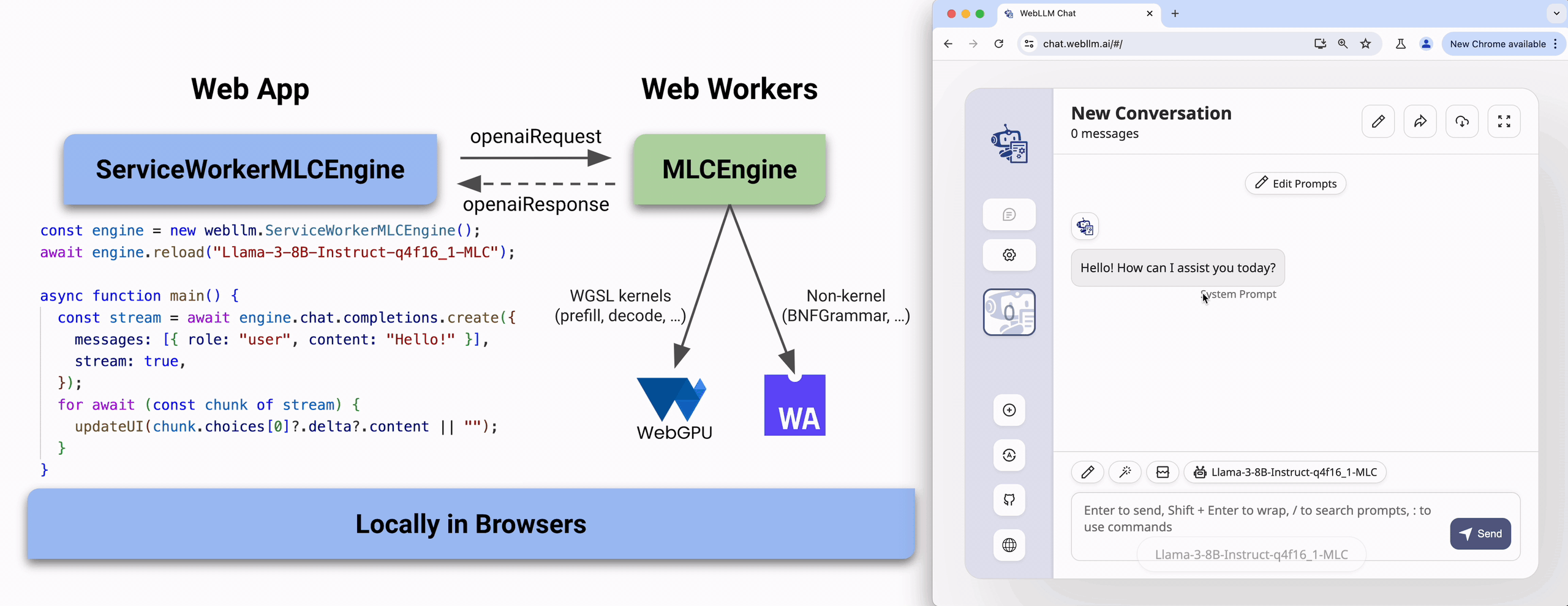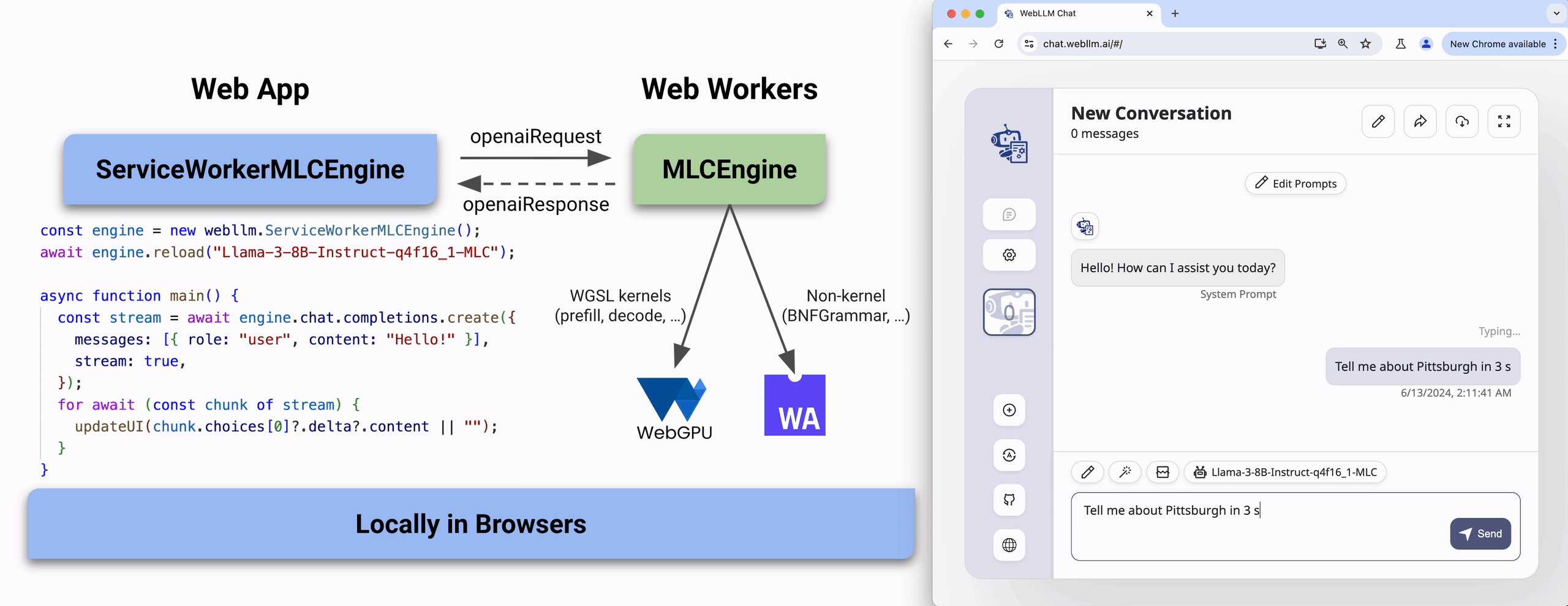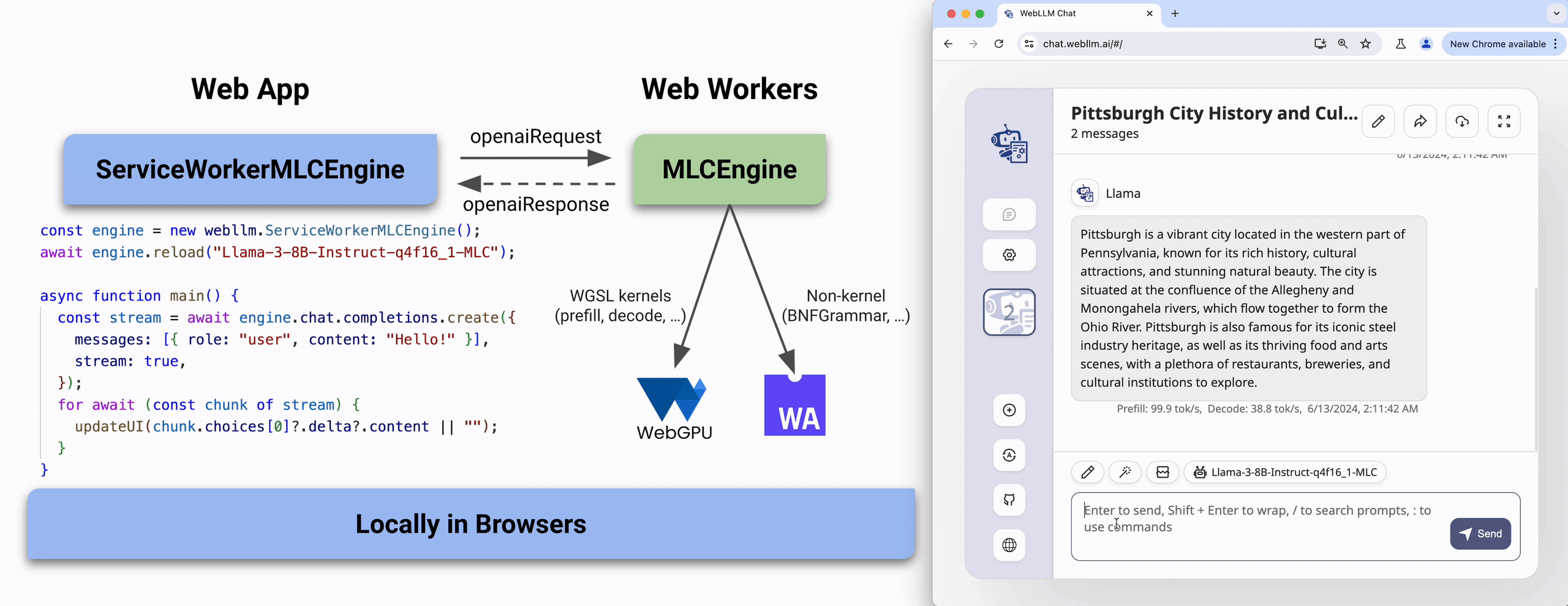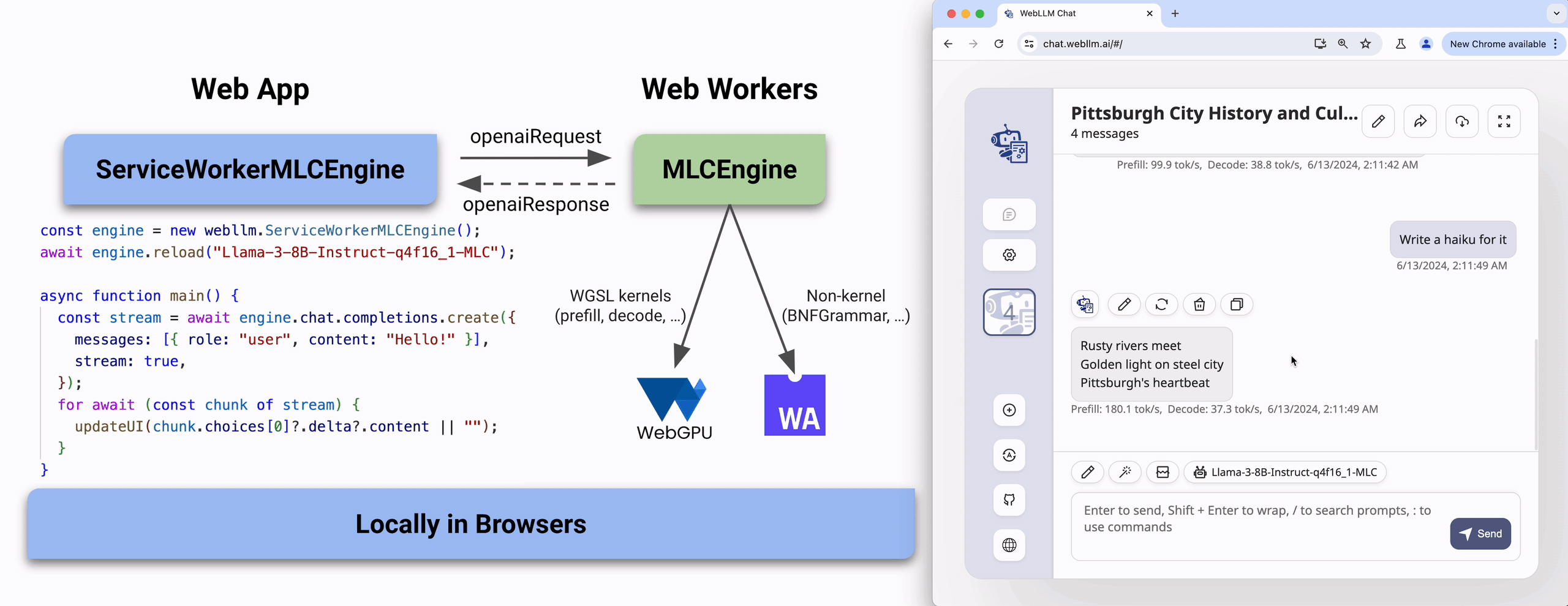
The MLC-AI team has developed the website: https://chat.webllm.ai/ allows you to download and try a wide range of LLMs locally in the browser without any installation or configuration. It can give a quick overview of how webLLM works and how to use it.