GraphQL + Netflix DGS + Spring Boot Kotlin: The Dream Team for Modern APIs
GraphQL + Netflix DGS + Spring Boot Kotlin: The Dream Team for Modern APIs
By Mohammad Hosseini
11 min read
In the rapidly evolving landscape of API development, GraphQL has emerged as a powerful alternative to traditional REST APIs. When combined with Netflix’s Domain Graph Service (DGS) framework and the robustness of Spring Boot with Kotlin, developers can create highly efficient, type-safe, and scalable APIs. In this article, we’ll explore the advantages of this framework and how to set up and build a GraphQL API using these cutting-edge technologies.

- Authors

GraphQL + Netflix DGS + Spring Boot Kotlin: The Dream Team for Modern APIs
In today’s API-driven world, REST is starting to show its limits. You either fetch way too much data, or you end up making multiple round trips just to render a single page. Frontend teams get frustrated, backend teams fight schema drift, and performance takes a hit.
GraphQL is perfect for letting clients request precisely the data they need—nothing more, nothing less. This eliminates over- and under-fetching issues common with traditional REST APIs, making your applications more efficient. However, implementing a robust GraphQL service from scratch can be challenging.
This is where Netflix's Domain Graph Service (DGS) framework comes in. It's a production-ready GraphQL server for Spring Boot that powers billions of requests on the Netflix platform. By pairing it with Kotlin and Spring Boot, you get a powerful combination that streamlines development and provides:
🚀 Developer productivity: Concise, type-safe code with Kotlin.
⚡ Enterprise-grade features: DGS brings testing, metrics, and security out of the box.
🔗 Flexibility: GraphQL ensures frontend and backend teams move faster without stepping on each other.

In this article, I’ll show you why GraphQL + Netflix DGS + Spring Boot Kotlin is a dream team for modern APIs — and how to set it up with real-world examples.
What is GraphQL?
GraphQL is a query language and runtime for APIs that was developed by Facebook in 2012 and open-sourced in 2015. Unlike REST APIs that expose multiple endpoints for different resources, GraphQL provides a single endpoint that allows clients to request exactly the data they need.
Key Benefits of GraphQL
Precise Data Fetching: Clients can specify exactly what data they need, reducing over-fetching and under-fetching problems common with REST APIs.
Strong Type System: GraphQL APIs are defined by a schema that serves as a contract between client and server, providing excellent tooling and validation capabilities.
Single Request, Multiple Resources: Complex queries can fetch related data in a single request, reducing the number of network calls.
Introspection: GraphQL schemas are self-documenting, allowing for powerful development tools and automatic API documentation.
Introducing Netflix DGS (Domain Graph Service)
Netflix DGS is a GraphQL server framework for Spring Boot that makes it easy to build GraphQL services in Java and Kotlin. Built by Netflix's engineering team to handle their massive scale, DGS provides a developer-friendly approach to GraphQL implementation.
Why Choose Netflix DGS?
Spring Boot Integration: Seamless integration with the Spring ecosystem, leveraging familiar patterns and configurations.
Supports Code-First Approach: Define your GraphQL schema using annotations directly in your code, eliminating the need to maintain separate schema files.
Built-in Testing Support: Comprehensive testing utilities that make it easy to test your GraphQL endpoints.
Production-Ready Features: Includes metrics, tracing, and security features needed for enterprise applications.
Kotlin Support: First-class support for Kotlin, taking advantage of its concise syntax and null safety.
Why This Stack Rocks
Picture this: You're tired of REST APIs where you either get way too much data or have to make 17 different calls just to render one page. Sound familiar? GraphQL solves this, but the real magic happens when you pair it with Netflix DGS (Domain Graph Service) and Kotlin.
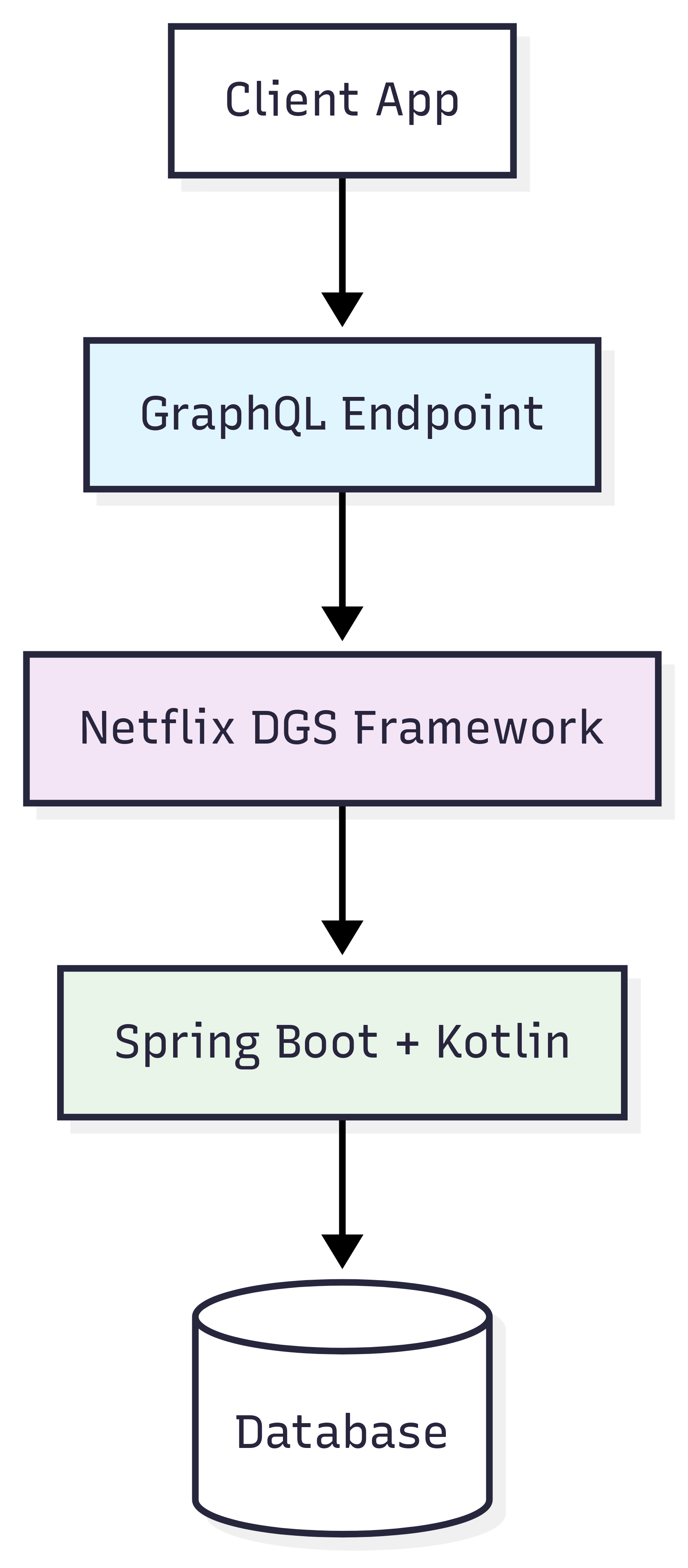
GraphQL gives you that "ask for exactly what you need" superpower. Netflix DGS makes it dead simple to build GraphQL services (and Netflix knows a thing or two about scale). Spring Boot handles all the boring stuff. Kotlin makes your code actually readable and safe.
Netflix DGS: The Real MVP
Let's be honest - building GraphQL servers used to be a pain. You'd have schema files here, resolvers there, and somehow they never stayed in sync. Netflix DGS said "nah, let's fix this" and gave us annotations that Just Work™.

Okay, enough theory. Let’s roll up our sleeves and actually build something.
Getting Started: The Fun Part
Project Setup
Your build.gradle.kts is pretty straightforward:
dependencies {
implementation("org.springframework.boot:spring-boot-starter-web")
implementation("org.springframework.boot:spring-boot-starter-data-jpa")
implementation("com.netflix.graphql.dgs:graphql-dgs-spring-boot-starter:8.1.1")
implementation("com.fasterxml.jackson.module:jackson-module-kotlin")
// Your usual suspects...
}
Data Models That Make Sense
Let's build something fun - a book management system. Because who doesn't love books? 📚
@Entity
data class Book(
@Id @GeneratedValue val id: Long = 0,
val title: String,
val author: String,
val publicationYear: Int,
val isbn: String? = null,
val pageCount: Int? = null
)
Clean, simple, and Kotlin's data classes give you equals, hashCode, and toString for free.
The Magic: DGS Data Fetchers
Here’s the magic of DGS — it automatically maps the GraphQL BookInput type from your schema straight into a Kotlin data class with the same fields. No boilerplate, no hassle. Just clean and type-safe:
@DgsComponent
class BookDataFetcher {
@Autowired
lateinit var bookRepository: BookRepository
@DgsQuery
fun books(): List<Book> = bookRepository.findAll()
@DgsQuery
fun book(@InputArgument id: Long): Book? =
bookRepository.findById(id).orElse(null)
@DgsMutation
fun addBook(@InputArgument book: BookInput): Book {
val newBook = Book(
title = book.title,
author = book.author,
publicationYear = book.publicationYear,
isbn = book.isbn,
pageCount = book.pageCount
)
return bookRepository.save(newBook)
}
}
And that’s all it takes — no XML, no extra schema files, no heavy setup. Just annotate your methods and let DGS do the work. That said, the schema-first approach is still considered a best practice in most cases.
How It All Flows Together

Schema Definition
Create src/main/resources/schema/schema.graphqls:
type Query {
books: [Book]
book(id: ID!): Book
}
type Mutation {
addBook(book: BookInput!): Book
}
type Book {
id: ID!
title: String!
author: String!
publicationYear: Int!
isbn: String
pageCount: Int
}
input BookInput {
title: String!
author: String!
publicationYear: Int!
isbn: String
pageCount: Int
}
The Development Experience
One of the coolest things about this stack? Fire up your app and hit http://localhost:8080/graphiql. You get a beautiful GraphQL playground out of the box.

Try this query:
query GetBooks {
books {
id
title
author
publicationYear
}
}
And boom - you get exactly what you asked for, nothing more, nothing less.
Advanced Patterns (The Cool Stuff)
DataLoader Pattern: Solving the N+1 Problem
One of the biggest performance killers in GraphQL is the N+1 query problem. When you fetch a list of books and then request each book's author, you end up with 1 query for books + N queries for authors. DataLoader solves this elegantly.

Here's how to implement it:
@DgsDataLoader(name = "authors")
class AuthorDataLoader : BatchLoader<Long, Author> {
@Autowired
lateinit var authorRepository: AuthorRepository
override fun load(authorIds: List<Long>): CompletionStage<List<Author>> {
return CompletableFuture.supplyAsync {
// Single database query for all requested IDs
val authors = authorRepository.findAllById(authorIds)
// DataLoader requires results in the same order as input IDs
authorIds.map { id ->
authors.find { it.id == id }
}
}
}
}
// Use it in your resolver
@DgsData(parentType = "Book", field = "author")
fun bookAuthor(dfe: DataFetchingEnvironment): CompletableFuture<Author?> {
val book = dfe.getSource<Book>()
val dataLoader = dfe.getDataLoader<Long, Author>("authors")
return dataLoader.load(book.authorId)
}
The @DgsData annotation plays a key role here: it declares this function as the data fetcher for the author field on the Book type. This explicit mapping is what lets DGS connect the GraphQL schema to your Kotlin code, enabling the DataLoader to resolve that specific field efficiently. In other words: whenever a query asks for book { author }, DGS will call this function to resolve the author.
What DataLoader gives you:
- Automatic Batching: Collects all author requests during query execution and batches them
- Deduplication: If author ID 1 is requested multiple times, only fetches once
- Per-Request Caching: Results are cached for the duration of the GraphQL request
- Ordering Guarantee: Results returned in the same order as requested IDs
Error Handling
It can be useful to map application-specific exceptions to meaningful exceptions back to the client. The framework provides two different mechanisms to achieve this.
Spring
The @ControllerAdvice approach is the most idiomatic Spring way to handle exceptions globally, and it works seamlessly with DGS:
@ControllerAdvice
class ControllerExceptionHandler {
@GraphQlExceptionHandler
fun handle(ex: IllegalArgumentException): GraphQLError {
return GraphQLError.newError().errorType(ErrorType.BAD_REQUEST).message("Handled an IllegalArgumentException!").build();
}
}
This approach leverages Spring's familiar exception handling patterns that most developers already know and provides consistent behavior across your entire application.
Graphql-java
@DgsComponent
class CustomErrorHandler : DataFetchingExceptionHandler {
override fun onException(params: DataFetchingExceptionHandlerParameters): DataFetchingExceptionHandlerResult {
val error = when (params.exception) {
is ValidationException -> TypedGraphQLError.newBadRequestBuilder()
.message("Invalid input: ${params.exception.message}")
.build()
else -> TypedGraphQLError.newInternalErrorBuilder()
.message("Something went wrong")
.build()
}
return DataFetchingExceptionHandlerResult.newResult().error(error).build()
}
}
Query Validation and Protection
GraphQL is powerful because clients can request exactly what they need. However, this flexibility comes with risks: a single query can unintentionally (or maliciously) overload your server. Some key risks include:
Deeply Nested Queries: A client can request data several layers deep. Each nested field can trigger additional database or API calls, causing exponential growth in resource usage.
High Multiplicity Fields: Fields that return lists (e.g., books, reviews, posts) can dramatically increase the load if the query requests large first or limit values.
Expensive Computations: Some fields require heavy computation, like ML-based recommendations, aggregations, or complex joins. These fields may be cheap in isolation but extremely costly at scale.
Without limits, a query like this:
query {
books(first: 1000) {
reviews(first: 100) {
author {
books(first: 50) {
similarBooks {
title
}
}
}
}
}
}
can explode in cost—triggering tens of millions of operations—potentially crashing your server. To safeguard your GraphQL API, we assign costs to fields, calculate the total query complexity, and reject queries that exceed safe limits.
@Component
class QueryComplexityInstrumentation : Instrumentation {
override fun instrumentValidation(parameters: InstrumentationValidationParameters): InstrumentationContext<List<ValidationError>> {
return object : InstrumentationContext<List<ValidationError>> {
override fun onCompleted(result: List<ValidationError>, t: Throwable?) {
val complexity = calculateComplexity(parameters.document)
if (complexity > MAX_QUERY_COMPLEXITY) {
throw GraphQLException("Query too complex: $complexity (max: $MAX_QUERY_COMPLEXITY)")
}
}
}
}
private fun calculateComplexity(document: Document): Int {
// Analyze the query AST and calculate cost
// Consider factors like:
// - Field depth (deeply nested queries)
// - Array fields with high limits
// - Expensive computed fields
return complexityCalculator.calculate(document)
}
companion object {
const val MAX_QUERY_COMPLEXITY = 1000
}
}
Assign costs to fields and reject queries that exceed your "budget":
@Component
class QueryCostAnalyzer {
private val fieldCosts = mapOf(
"Book.reviews" to 10, // Reviews are expensive to fetch
"User.posts" to 5, // Posts moderate cost
"Book.similarBooks" to 50, // ML-based recommendations are expensive
"Book.title" to 1 // Simple fields are cheap
)
fun calculateCost(document: Document): Int {
var totalCost = 0
document.definitions.forEach { definition ->
if (definition is OperationDefinition) {
totalCost += calculateSelectionCost(definition.selectionSet, "Query")
}
}
return totalCost
}
private fun calculateSelectionCost(selectionSet: SelectionSet, parentType: String): Int {
var cost = 0
selectionSet.selections.forEach { selection ->
when (selection) {
is Field -> {
val fieldKey = "$parentType.${selection.name}"
val fieldCost = fieldCosts[fieldKey] ?: 1
// Apply multipliers for arguments like 'first'
val multiplier = selection.arguments
.find { it.name == "first" }
?.value?.let { (it as? IntValue)?.value?.toInt() } ?: 1
cost += fieldCost * multiplier
// Recursively calculate nested field costs
selection.selectionSet?.let { nestedSet ->
cost += calculateSelectionCost(nestedSet, getReturnType(fieldKey))
}
}
}
}
return cost
}
}
This prevents queries like:
query ExpensiveQuery {
books(first: 1000) {
# 1000 * base cost
reviews(first: 100) {
# 1000 * 100 * review cost = 100,000 points
author {
# Another 100,000 author lookups
books(first: 50) {
# Exponential explosion!
similarBooks {
# ML recommendations for each!
title
}
}
}
}
}
}
# Total cost: ~50,000,000 points - REJECTED!
Benefits of Query Complexity Analysis:
Prevents Denial of Service (DoS) attacks caused by expensive queries
Protects database and backend services from heavy load
Allows flexible yet safe GraphQL usage by clients
Encourages thoughtful schema design, e.g., limiting fields or providing pagination
Persisted Queries: Security and Performance
Instead of sending full query strings, clients send query hashes. This reduces payload size and prevents arbitrary query execution.
@Component
class PersistedQuerySupport {
private val queryStore = ConcurrentHashMap<String, String>()
fun registerQuery(hash: String, query: String) {
queryStore[hash] = query
}
fun getQuery(hash: String): String? {
return queryStore[hash]
}
}
// Client sends this instead of full query
{
"id": "abc123def456",
"variables": { "bookId": "789" }
}
Benefits:
- Reduced Bandwidth: Send tiny hash instead of full query
- Security: Only pre-approved queries can execute
- Caching: Queries can be cached more effectively
- Analytics: Track which queries are actually used
Field-Level Caching with Custom Directives
Cache expensive computations at the field level with configurable TTL:
@Component
class CacheDirective : SchemaDirectiveWiring {
private val cache = Caffeine.newBuilder()
.maximumSize(10000)
.expireAfterWrite(Duration.ofMinutes(5))
.build<String, Any>()
override fun onField(environment: SchemaDirectiveWiringEnvironment<GraphQLFieldDefinition>): GraphQLFieldDefinition {
val ttl = environment.directive.getArgument("ttl")?.argumentValue?.value as? Int ?: 300
val originalDataFetcher = environment.codeRegistry.getDataFetcher(
environment.fieldsContainer,
environment.element
)
val cachedDataFetcher = DataFetcher { env ->
val cacheKey = "${env.field.name}:${env.arguments.hashCode()}"
cache.get(cacheKey) {
originalDataFetcher.get(env)
}
}
environment.codeRegistry.dataFetcher(
environment.fieldsContainer,
environment.element,
cachedDataFetcher
)
return environment.element
}
}
Usage in schema:
directive @cache(ttl: Int = 300) on FIELD_DEFINITION
type Book {
title: String!
author: String!
averageRating: Float @cache(ttl: 1800) # Cache for 30 minutes
similarBooks: [Book!]! @cache(ttl: 3600) # Cache for 1 hour
realTimeViews: Int # No caching
}
Relay Cursor Connections: Standardized Pagination
Instead of simple offset/limit pagination, Relay connections provide stable, cursor-based pagination that works well with real-time data.
@DgsQuery
fun books(
@InputArgument first: Int?,
@InputArgument after: String?,
@InputArgument last: Int?,
@InputArgument before: String?
): BookConnection {
val pageSize = first ?: last ?: 10
val cursor = after ?: before
val books = bookRepository.findBooksAfterCursor(cursor, pageSize + 1)
val hasNextPage = books.size > pageSize
val edges = books.take(pageSize).map { book ->
BookEdge(
node = book,
cursor = encodeCursor(book.id)
)
}
return BookConnection(
edges = edges,
pageInfo = PageInfo(
hasNextPage = hasNextPage,
hasPreviousPage = cursor != null,
startCursor = edges.firstOrNull()?.cursor,
endCursor = edges.lastOrNull()?.cursor
)
)
}
Schema definition:
type BookConnection {
edges: [BookEdge!]!
pageInfo: PageInfo!
}
type BookEdge {
node: Book!
cursor: String!
}
type PageInfo {
hasNextPage: Boolean!
hasPreviousPage: Boolean!
startCursor: String
endCursor: String
}
Why cursor pagination is better:
- Stable: New items won't shift your pagination
- Consistent: Works with real-time data updates
- Efficient: Database can optimize cursor-based queries
- Standardized: Relay spec means tooling support
Union Types and Interfaces: Flexible Type Systems
Handle heterogeneous data elegantly with GraphQL's advanced type system:
// Interface for common fields
interface SearchResult {
val id: String
val title: String
val relevanceScore: Float
}
// Implementations
data class Book(
override val id: String,
override val title: String,
override val relevanceScore: Float,
val author: String,
val isbn: String
) : SearchResult
data class Author(
override val id: String,
override val title: String, // Author name as title
override val relevanceScore: Float,
val biography: String,
val birthYear: Int?
) : SearchResult
// Union resolver
@DgsTypeResolver(name = "SearchResult")
class SearchResultTypeResolver : TypeResolver {
override fun getType(env: TypeResolutionEnvironment): GraphQLObjectType {
return when (env.getObject<Any>()) {
is Book -> env.schema.getObjectType("Book")
is Author -> env.schema.getObjectType("Author")
else -> throw RuntimeException("Unknown search result type")
}
}
}
Schema:
interface SearchResult {
id: ID!
title: String!
relevanceScore: Float!
}
type Book implements SearchResult {
id: ID!
title: String!
relevanceScore: Float!
author: String!
isbn: String!
}
type Author implements SearchResult {
id: ID!
title: String!
relevanceScore: Float!
biography: String!
birthYear: Int
}
union SearchResult = Book | Author
type Query {
search(query: String!): [SearchResult!]!
}
Client usage:
query Search($query: String!) {
search(query: $query) {
... on Book {
author
isbn
}
... on Author {
biography
birthYear
}
# Common fields available on all results
id
title
relevanceScore
}
}
Real-World Query Examples
Here's what your frontend team will love you for:
# Get everything
query GetAllBookInfo {
books {
id
title
author
publicationYear
pageCount
isbn
}
}
# Get just what you need for a list
query GetBookList {
books {
id
title
author
}
}
# Search with variables
query SearchBooks($title: String, $author: String) {
searchBooks(title: $title, author: $author) {
id
title
author
publicationYear
}
}
Configuration That Just Works
Your application.yml:
dgs:
graphql:
graphiql:
enabled: true
schema-locations:
- 'classpath*:schema/**/*.graphql*'
That's literally it for the basic setup for the backend.
The JavaScript Client Experience
Your frontend developers will thank you. Here's how easy it is to consume your API:
// Using Apollo Client
const GET_BOOKS = gql`
query GetBooks {
books {
id
title
author
publicationYear
}
}
`
function BookList() {
const { loading, error, data } = useQuery(GET_BOOKS)
if (loading) return <p>Loading...</p>
if (error) return <p>Error: {error.message}</p>
return (
<ul>
{data.books.map((book) => (
<li key={book.id}>
{book.title} by {book.author} ({book.publicationYear})
</li>
))}
</ul>
)
}
Key Technical Advantages for Enterprise Development

Type Safety Everywhere: Kotlin's null safety + GraphQL's strong typing = fewer bugs in production.
No Schema Drift: Your code IS your schema. They can't get out of sync because they're the same thing.
Spring Boot Ecosystem: All your favorite Spring features just work. Security, data, caching - it's all there.
Netflix Scale: This isn't some toy framework. Netflix uses this to serve billions of requests.
Conclusion
GraphQL with Netflix DGS and Spring Boot Kotlin provides a powerful combination for building modern, efficient APIs. The type safety of Kotlin, combined with the flexibility of GraphQL and the production-ready features of DGS, creates an excellent developer experience while delivering high-performance applications.
Key takeaways from this setup:
- Developer Experience: The combination of Kotlin's concise syntax and DGS annotations makes GraphQL development intuitive and productive.
- Type Safety: Both Kotlin and GraphQL's strong typing systems work together to catch errors at compile time.
- Performance: Built-in features like DataLoader help optimize database queries and improve response times.
- Testing: DGS provides excellent testing utilities that make it easy to verify your GraphQL endpoints.
- Production Ready: Netflix DGS includes monitoring, metrics, and security features needed for enterprise applications.
This approach scales well from simple APIs to complex microservice architectures, making it an excellent choice for modern application development. The GraphQL ecosystem continues to mature, and with tools like Netflix DGS, building robust GraphQL APIs has never been easier.
