Discover HTTP/3
Discover HTTP/3
By Lucien Immink
5 min read
What is HTTP/3 and how does it differ from HTTP/2? In order to understand we need to dive deep into how the protocols of the internet work.
- Authors

- Name
- Lucien Immink
I remember as if it was only yesterday that HTTP/2 was introduced and now HTTP/3 is here. HTTP/3 used to be called HTTP/2 Semantics using the QUIC transport protocol, so HTTP/3 is HTTP/2 and what is QUIC? Let me clarify that for you!
To understand what HTTP/3 is and how it differs from HTTP/2, we first need to take a deep dive into what HTTP is. Ah yes HTTP: good old Hypertext Transfer Protocol which was of course initiated by Tim Berners-Lee in 1989 whilst he was working at CERN.
HTTP
HTTP is a request-response protocol which is used in client-server communication between computers. The client submits a request using a predefined method (like GET or POST) and the server will handle that request and in return returns a response, which can be anything from text, binary data to nothing more than just a header (for example a 404 to indicate that the requested resource is not found).
The protocol allows intermediate networks to alter / extend / improve / open communications. Take for example a proxy: This server can return the resource - if present - to improve the response time. A proxy can also be used as a relay for clients that are not allowed external access.
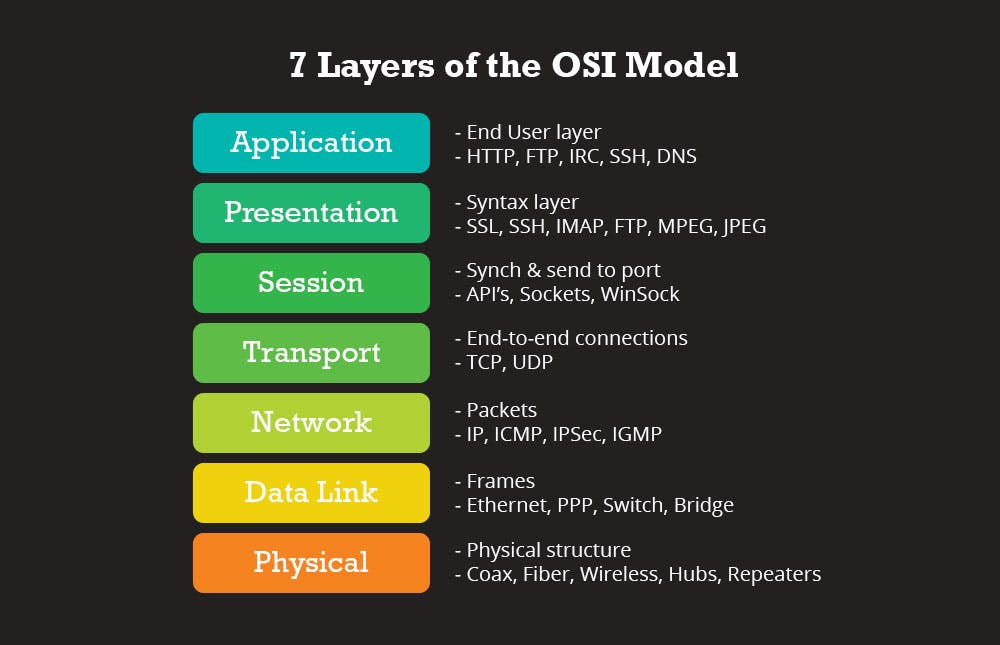
HTTP is an application layer protocol as described in the OSI model and presumes an underlying network protocol like Internet Protocol(IP) and transport protocol Transmission Control Protocol (TCP), it can however be adopted to use other transport protocols like User Datagram Protocol (UDP).
A HTTP resource is identified by the Uniform Resource Locators (URLs) which consists of following key elements:

- (scheme)
- (authority [= username@host:port])
- (path)
- (query)
- (fragment)
Parts of the URL are optional and omitting them can have both positive and negative side-effects. For navigating between resources:
- No scheme means that the resource requested should use the same scheme as the requestee. This can easily fix mixed-content errors. HTTPS stays HTTPS! (for example: //www.example.com)
- No scheme and no authority means that the resource requested should be on the same domain, if the URL starts with a forward-slash (/) the requested resource is requested using the absolutepath otherwise it is relative to the requestee (/articles/ vs articles/).
- No scheme and no authority and no path indicate that the requested resource should be found in the same path as the requestee (for example: page2.html)
While query and fragment won’t change what the requested resource is a query does alter the response. If sent, the query is used as a filter (or it should be 😉). The fragment is fully client side and was intended to be used as a bookmark so the page would scroll to a specific element in the HTML element. Because the fragment will not trigger a navigation event in the browser it was also used a lot for client-side navigation (known as hashbang note that that link uses a fragment).
HTTP/1.1 improved the original 1.0 by reusing a connection multiple times to download resources after the original page has been delivered. This results in less latency as the underlying TCP protocol overhead for setting up the connection is not needed anymore (once it is set up).
HTTP/2
It took a while before HTTP/1.1 (from 1997) was succeeded, but in 2015 the HTTP/2 specifications were officially published. The main goals for HTTP/2 were:
- Maintain high-level compatibility with HTTP/1.1 (for example with methods, status codes, URIs, and most header fields).
- Decrease latency to improve page load speed in web browsers by considering:
- data compression of HTTP headers
- HTTP/2 Server Push
- pipelining of requests
- fixing the head-of-line blocking problem in HTTP 1.x
- multiplexing multiple requests over a single TCP connection
- Support common existing use cases of HTTP.
With these goals the migration from HTTP/1.1 to HTTP/2 is transparent for the client. The URL remains the same and the response remains the same except for that if the HTTP/2 protocol is used more and better compression becomes available as well as multiplexing and pipelining requests to reduce the TCP overhead even further. HTTP/2 Server Push enables a server to send additional data to a connected client afterthe requested resource is send.
Although not part of the standard all major clients only support HTTP/2 over TLS which makes encryption of the connection mandatory and is now considered a must for HTTP/2.
HTTP/3
As of December 2020, the HTTP/3 protocol is an internet draft and implementation for both servers and clients has started. Major browser vendors have HTTP/3 behind a feature flag and Safari has it enabled by default since version 14 on macOS Big Sur.
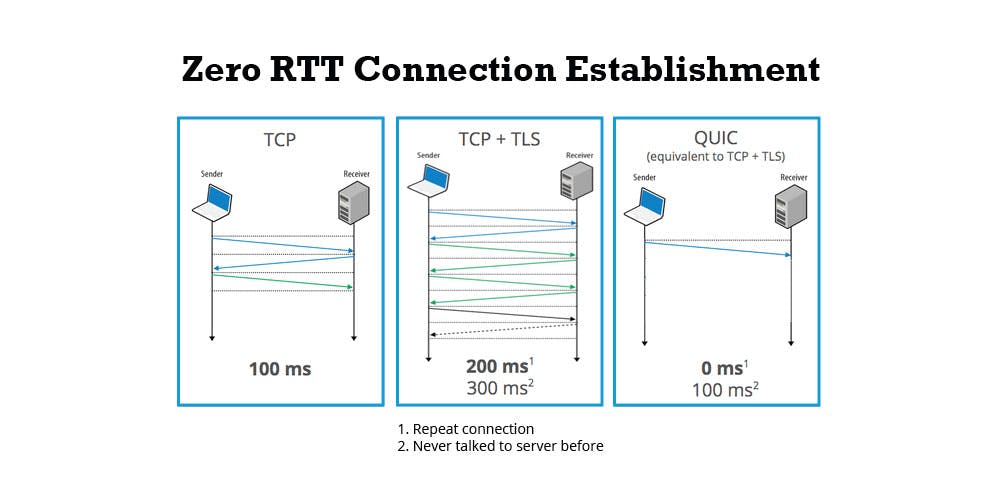
The big change here is the use of QUIC as transport layer protocol instead of TCP. QUIC improves performance of web-based applications by establishing several multiplexed connections between server and client using UDP and is designed to replace TCP.
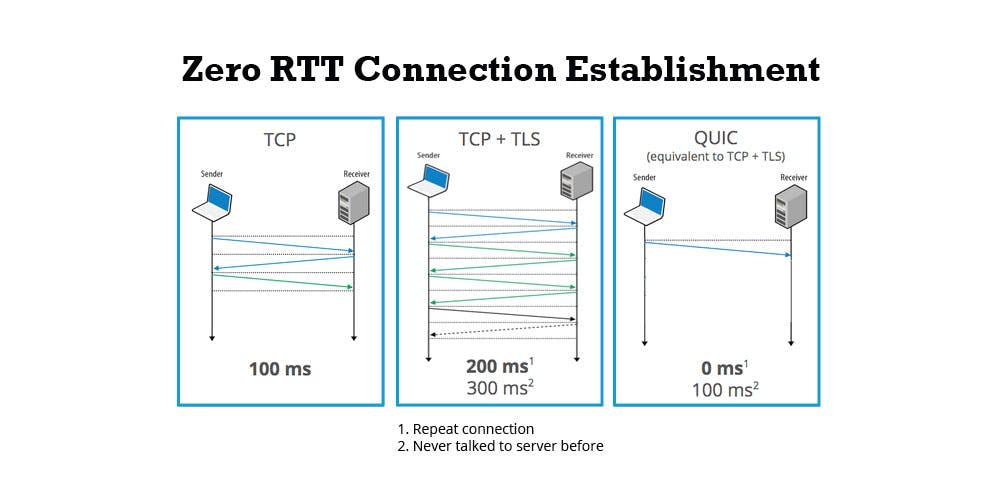
Reading back HTTP/3 is HTTP/2 using a different transport protocol, so why is it called HTTP/3 then? At first it was named HTTP/2 Semantics Using The QUIC Transport Protocol and later renamed to HTTP over QUIC but to make clear that the protocol is separate from QUIC itself and thus should not have the QUIC in it, it was renamed to HTTP/3.
HTTP/3 enables the QUIC protocol for HTTP/2.